What is the Difference Between Data Redundancy and Data Inconsistency? with Proper Definition and Brief Explanation
The main difference between data redundancy and data inconsistency is that data redundancy is a condition that occurs when the same piece of data exists in multiple places in the database whereas data inconsistency is a A condition that occurs when the same data exists in different formats in multiple tables.
A database is a collection of data. DBMS (Database Management System) is software that helps manage databases. Introduced around the year 1960, it can handle a large collection of data. Also, it helps to easily create, retrieve, update and delete data. DBMS allows multiple users to access data simultaneously and provides data security. Data redundancy and data inconsistency are two terms related to DBMS.
Key Areas Covered
1. What is data redundancy?
– Definition, Functionality
2. What is data inconsistency?
– Definition, Functionality
3. What is the difference between data redundancy and data inconsistency?
– Comparison of key differences
Key terms
Data inconsistency, data redundancy

What is data redundancy?
Data redundancy refers to the same data located in multiple places in the database. It clutters the database with unnecessary information. It also makes data recovery less efficient. Also, data redundancy consumes more resources in the database. Over time, data redundancy causes the database to become corrupted, making the data unusable.
For example, suppose a table in the school database. You have a table called student as follows.

Students 1 and 2 are learning from teacher P, and students 3 and 4 are learning from teacher Q. Here, the teacher id and teacher name are repeated twice. Instead, the teacher ID and teacher name can be stored in a separate table. The new student table and teacher table are as follows.
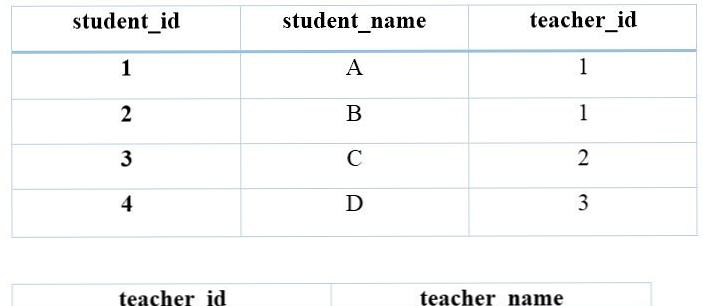
The solution is data redundancy is normalization. Reduce data redundancy and make data more meaningful.
What is data inconsistency
Data inconsistency refers to a situation of keeping the same data in different formats in two different tables or a situation where data between tables is required to match. However, this can cause one table in the database to have the correct value and the remaining tables to be different. It can also cause unreliable and meaningless information. Also, it is difficult to reduce data inconsistency.
For example, suppose a hospital database. Changing a patient’s address can affect many other tables. Only one record will have correct data, while the others will have false data. So this is data inconsistency. Causes the hospital administration to check various records for the correct address of the patient. It occurs because the same data that resides in multiple places is not updated. Using proper constraints within the database is a solution to prevent data inconsistency.
Relationship between data redundancy and data inconsistency
- Data redundancy can cause data inconsistency.
Difference Between Data Redundancy and Data Inconsistency
Definition
Data redundancy is a condition that occurs within a database or data storage technology in which the same piece of data can be found in two or more separate places. Whereas, data inconsistency is a condition that occurs between tables when we keep similar data in different formats in two different tables, or when data comparison between tables is a necessity. These definitions therefore explain the main difference between them.
Prevention
Prevention is the other main difference between them. Normalization helps minimize data redundancy. However, the use of constraints in the database helps prevent data inconsistency.
Conclusion
In general, data redundancy and data inconsistency are two terms related to DBMS. The main difference between them is that data redundancy is a condition that occurs when the same piece of data exists in multiple places in the database, while the other one is a condition that occurs when the same data exists in different formats in multiple tables.
Reference:
1. Reference from “What is Data Redundancy?”, IAC Publication, Available here.
2. Reference to “What is the definition of data inconsistency?”, IAC Publication, available here.
Courtesy image:
1.”1954920” (CC0) via Pixabay